15-Meta Learning(元學習)
1. 什麼是 Meta Learning?
將訓練資料輸入進 , 直接輸出一個模型 可以直接進行測試
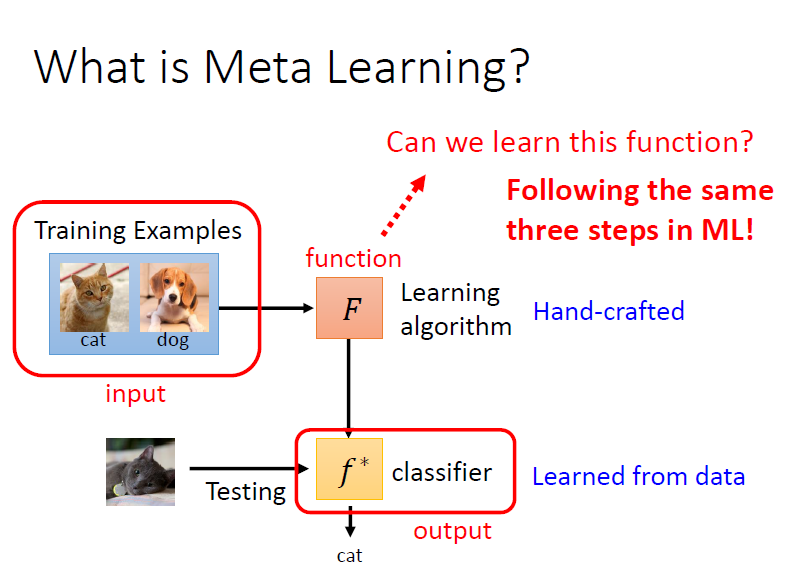
meta learning 就是要找一個 learning algorithm
2. 尋找 Learning Algorithm 三步驟
注意:
任務有訓練任務與測試任務之別
Step 1:What is learnable?
決定 learning algorithm 中要被學的 components(網路架構、初始參數、學習率等等),以 表示
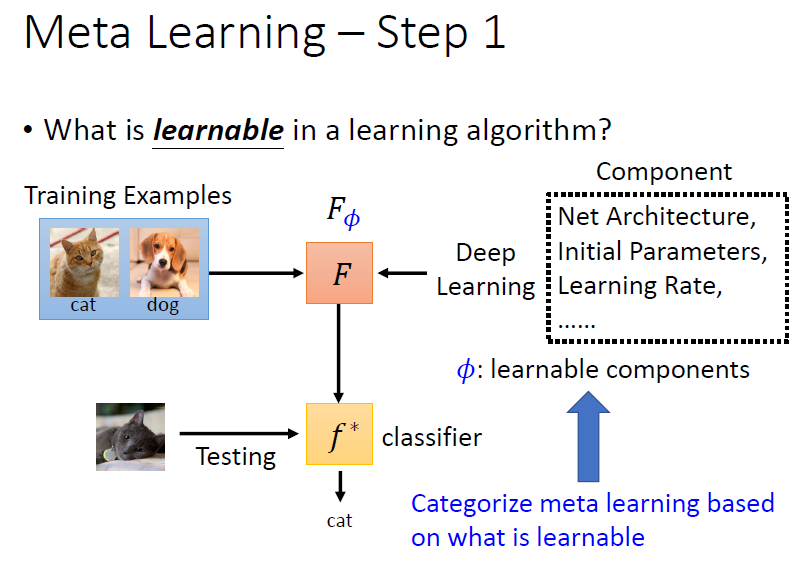
不同的 meta learning 方法的差異在於 components 的選擇
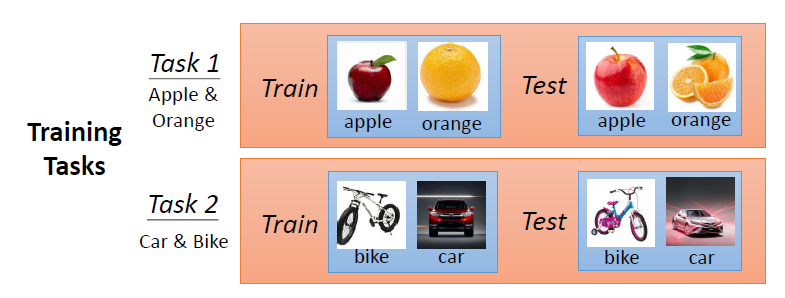
Step 2:Define loss function
訓練資料來自很多訓練任務,每個任務中有訓練集和測試集
定義 loss function :
- 將某一任務的訓練資料輸入進 learning algorithm ,得到模型
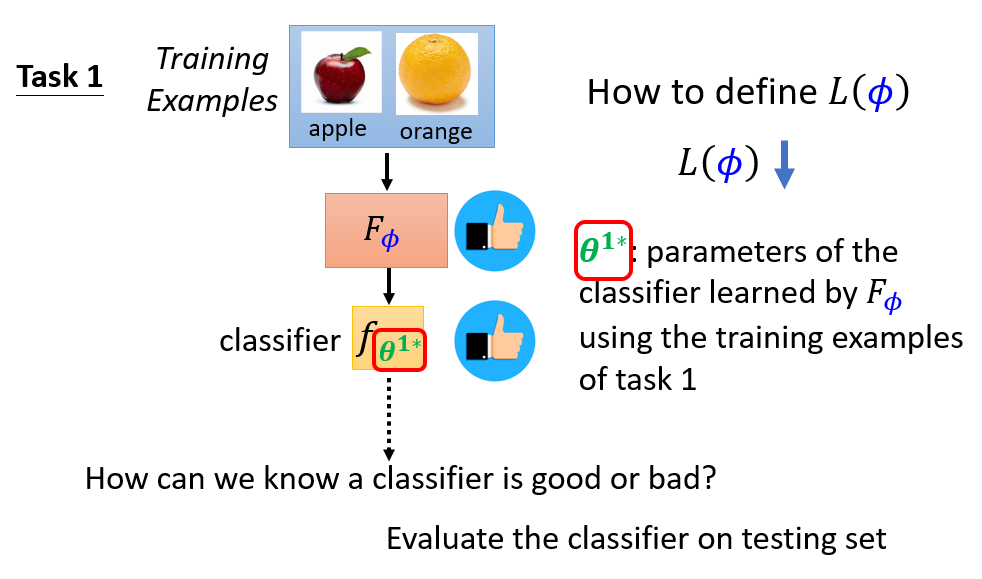
- 使用對應任務的測試資料對模型 進行測試,計算每個預測資料的結果與 ground truth 之間的 cross entropy,並將全部的 cross entropy 加總得到
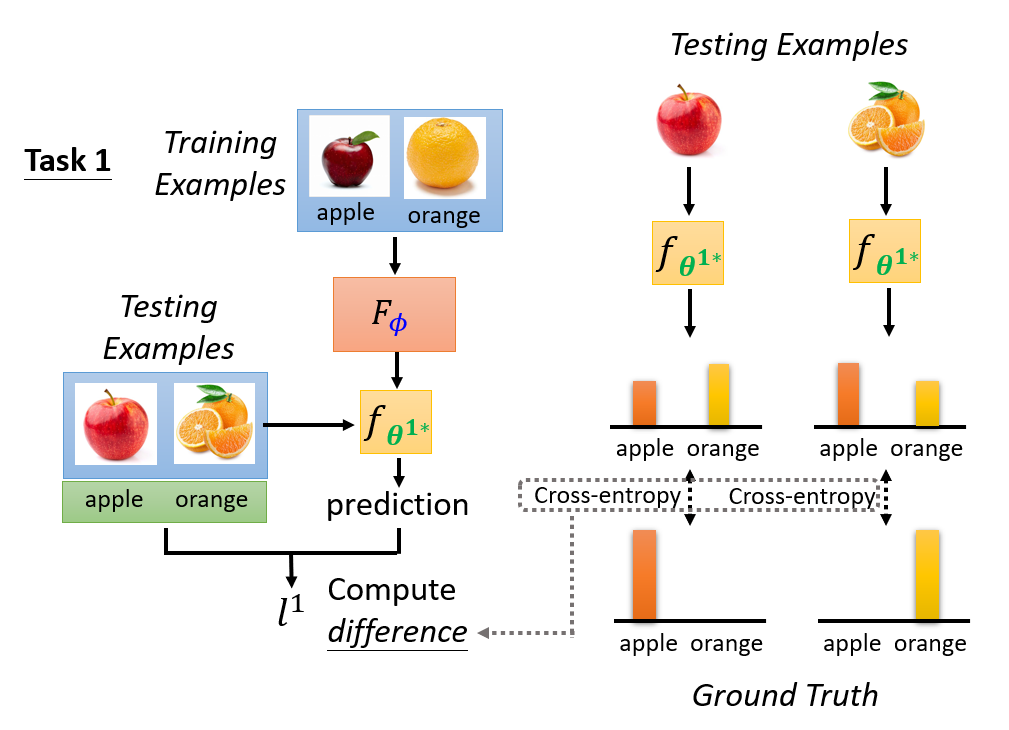
- 若越小,表示模型 越好,代表是好 learning algorithm
- 若越大,表示模型 越不好,代表是差 learning algorithm
- 將下一任務的訓練資料輸入進 learning algorithm ,得到模型 ,並計算每個預測資料的結果與 ground truth 之間的 cross entropy,並將全部的 cross entropy 加總得到
- 以此類推得到全部訓練任務的 ,並加總得到 learning algorithm 的 loss
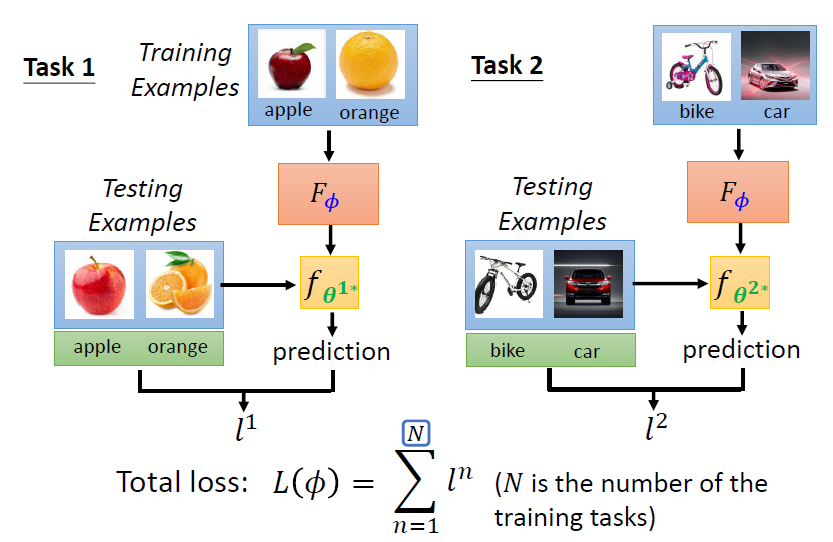
注意:
在一般機器學習中,loss 是根據訓練資料得來的;而在 meta learning 中,loss 是根據訓練任務中的測試資料得來的
Step 3:Optimazation

- 若 可微,則可以使用 gradient descent 找出 最小化
- 若 不可微( 有可能是一個 network 架構),使用 RL 硬 train,或其他方法
最終得到一 learning algorithm 使 最小化
Framework
我們真正關心的是在測試任務上,learning algorithm 的性能
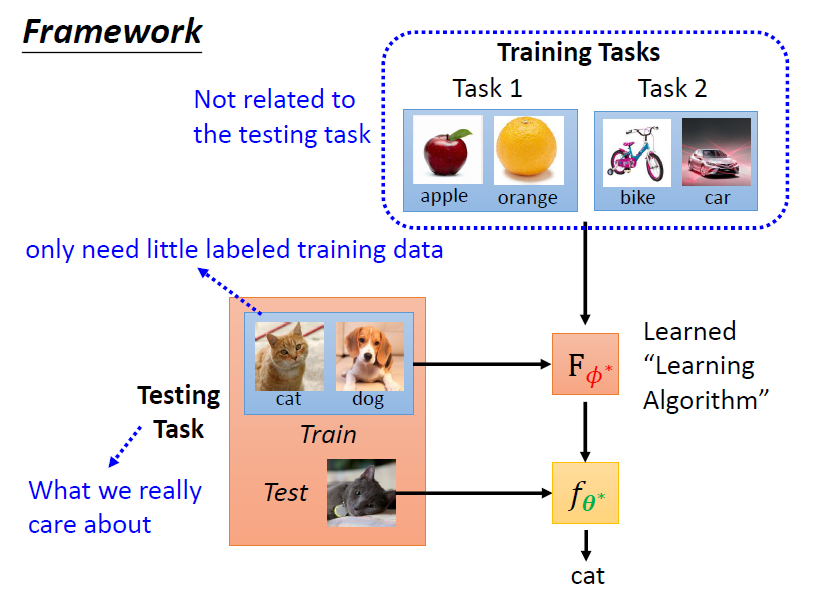
將測試任務中的訓練資料輸入進 learning algorithm 進行訓練得到模型 , 就是我們最終想要的模型
3. ML vs Meta
3.1 Goal
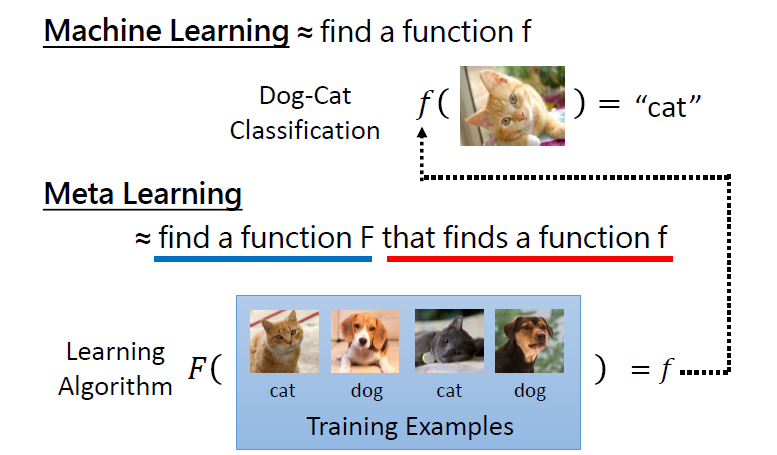
- ML:找到一個能完成任務的函數
- Meta:找到一個 learning algorithm ,能夠找到能完成任務的函數
3.2 Training Data
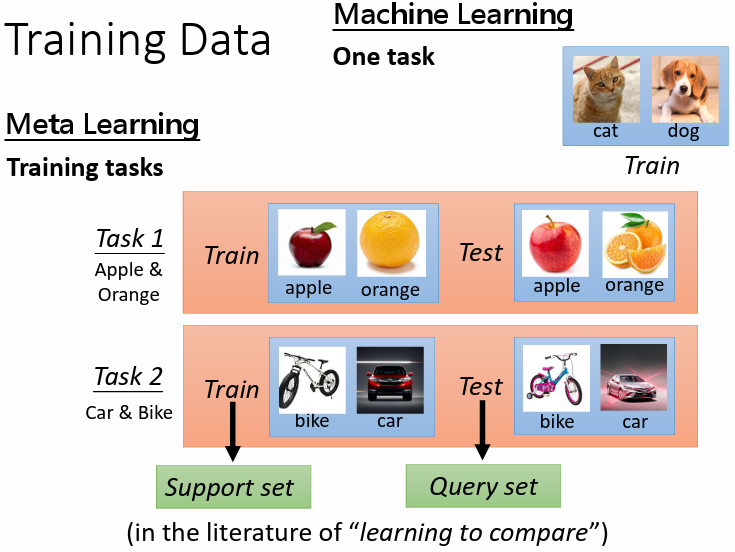
- ML:使用一個任務中的訓練資料進行訓練
- Meta:使用若干個訓練任務進行訓練,每個訓練任務中都有訓練資料及測試資料
- Support set:訓練任務中的訓練資料
- Query set:訓練任務中的測試資料
3.3 Framework
3.3.1 Training
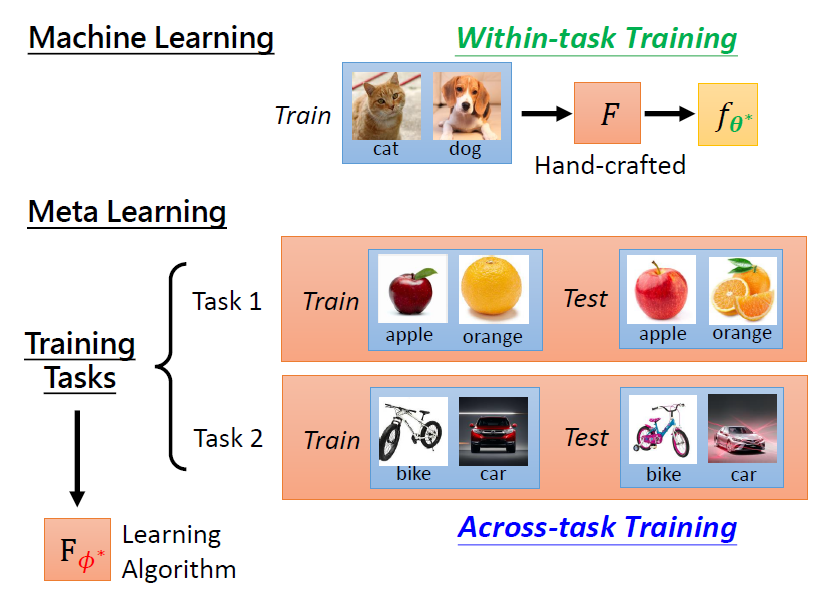
- ML:人為設定 learning algorithm,稱作 Within-task Training
- Meta:多個任務上訓練得到 learning algorithm,稱作 Across-task Training
3.3.2 Testing
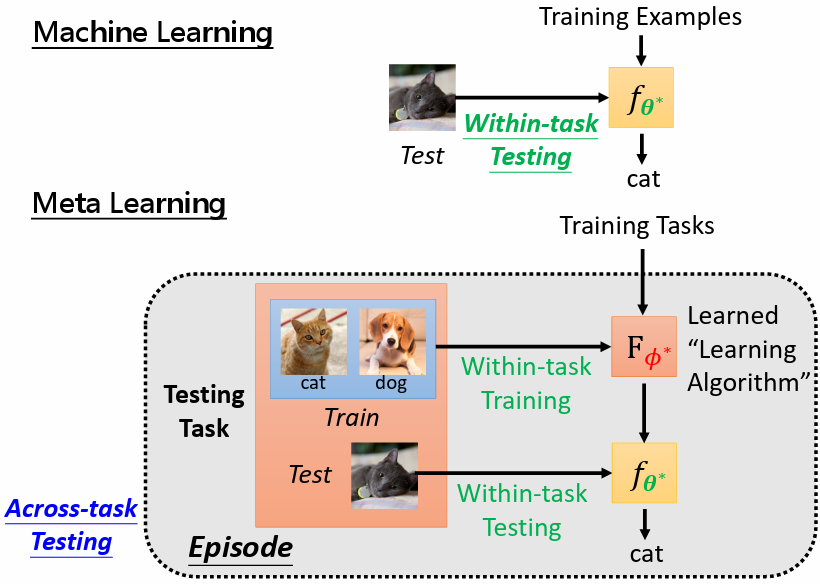
- ML:直接使用訓練得到的模型在任務中對測試資料進行測試,稱作 Within-task Testing
- Meta:需要測試的是 learning algorithm,稱作 Across-task Testing
- learning algorithm 以測試任務的訓練資料做為訓練,稱作 Within-task Training
- 以測試任務的測試資料測試模型,稱作 Within-task Testing
Episode = Within-task Training + Within-task Testing
3.3.3 Loss
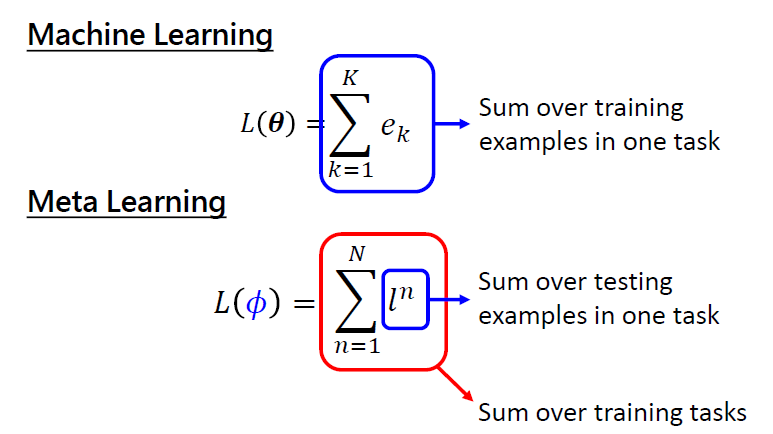
- ML:對一個任務中所有的測試數據的損失之和
- Meta: 是一個訓練任務的 loss, 是所有訓練任務的 loss 總和
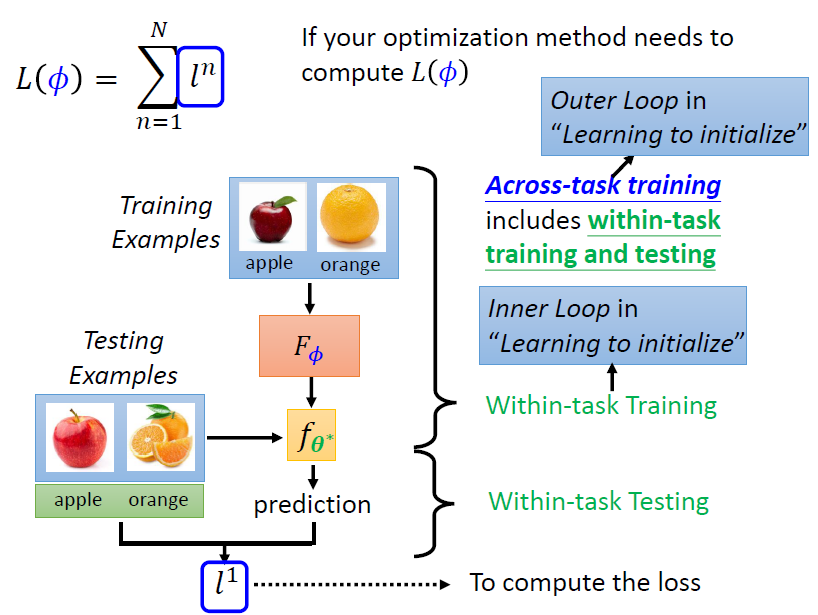
計算一個 ,需要一次的 Within-task Training + Within-task Testing 即一個 episode。將 Within-task Training 稱作 Inner Loop;Across-task training 稱作 Outer Loop
3.4 相同點

4. What is learnable in a learning algorithm?
4.1 模型初始參數
選擇 作為 meta learning 要學習的參數
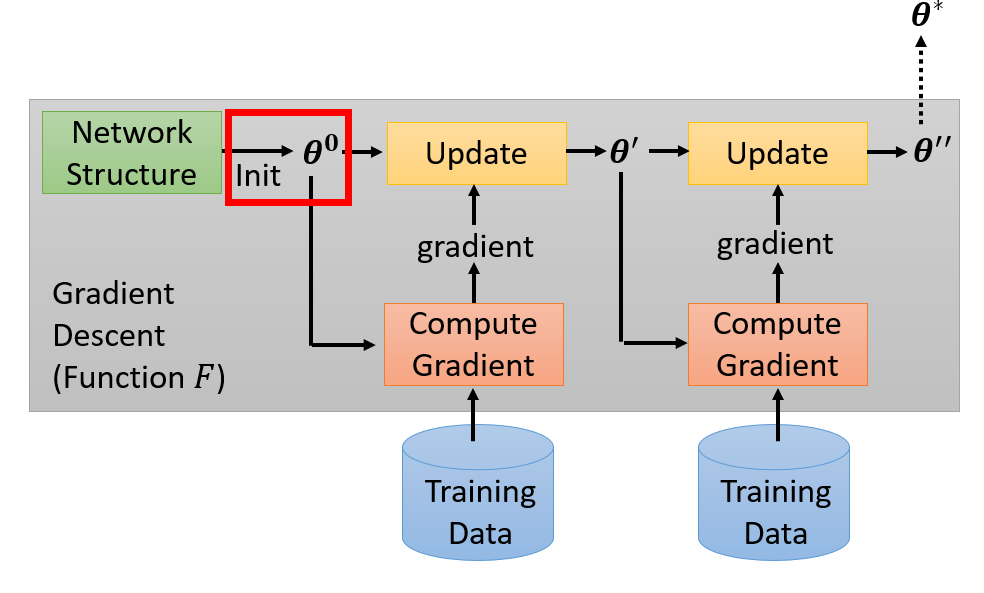
方法:
- Model Agnostic MetaLearning(MAML):https://youtu.be/mxqzGwP_Qys
- First order MAML(FOMAML):https://youtu.be/3z997JhL9Oo
- Reptile:https://youtu.be/9jJe2AD35P8
4.1.1 MAML vs Pre-training
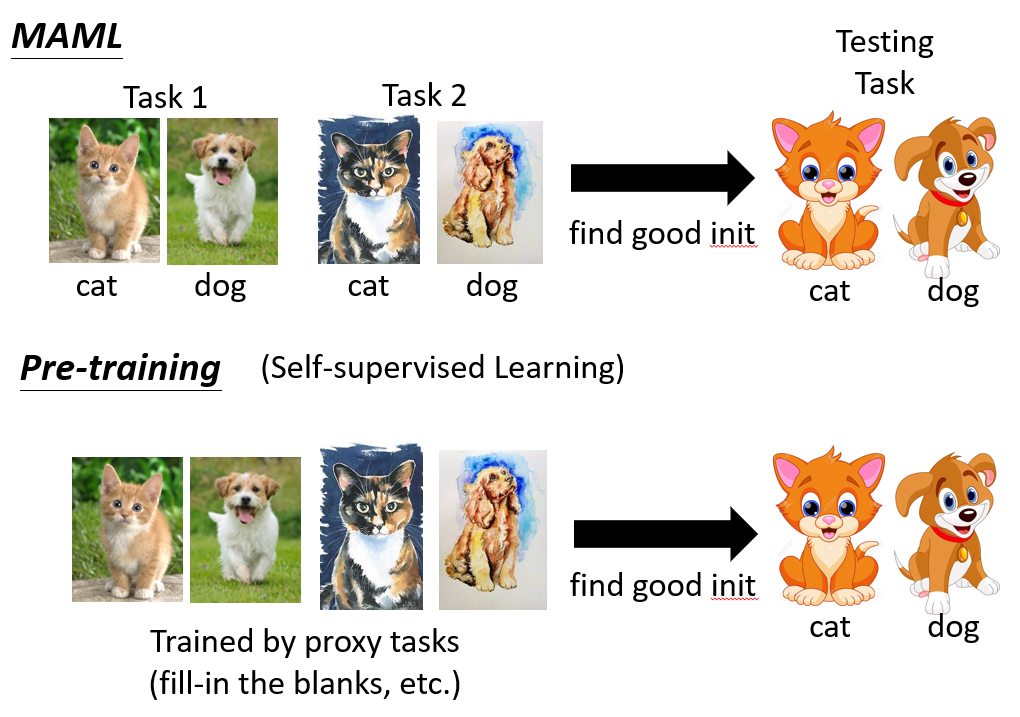
- MAML 需要用到有標註的資料
注意:
meta learning 中所謂不同任務的訓練,實際上就是不同的 domain,所以也可以說 meta learning 是 domain adaptation 的一種方法
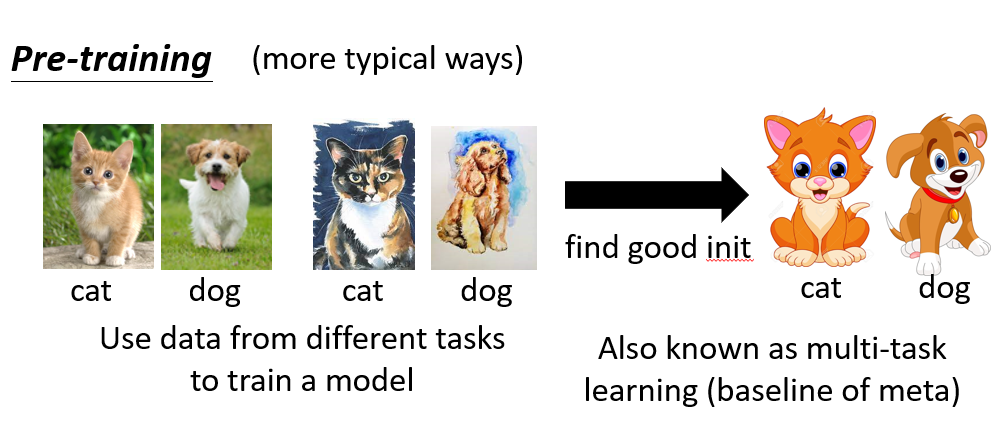
過去 pre-training 還有其他的方法,如將來自不同任務的資料混在一起進行訓練(稱作 multi-task training)
multi-task training 通常作為 meta-learning 的 baseline
學習更多:
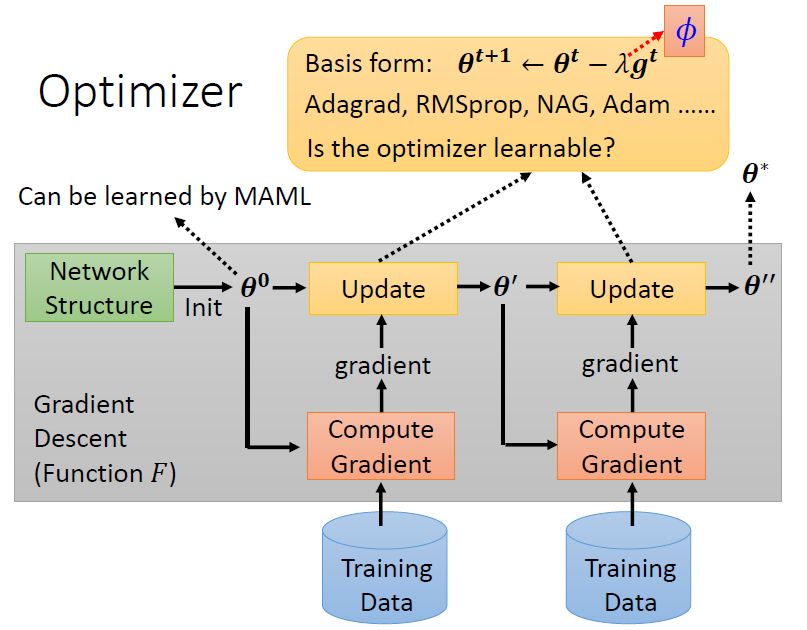
4.2 Optimizer(learning rate, momentum)
選擇 learning rate, momentum 等 optimizer 中的參數作為 meta learning 要學習的參數
4.3 Network Architecture Search(NAS)
選擇 network 架構作為 meta learning 要學習的參數
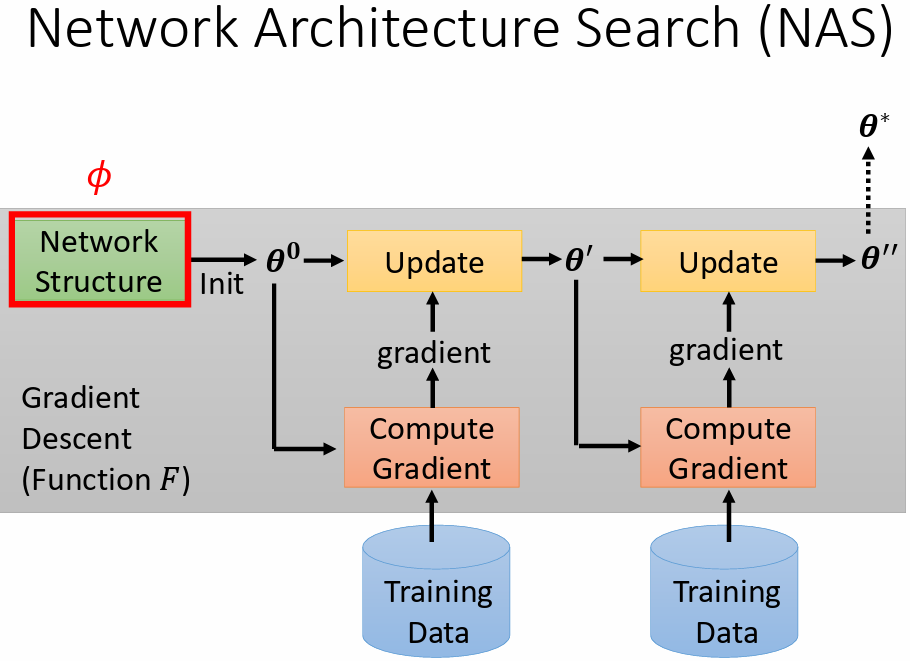
問題:
是一個 network 架構, 對 不可微
4.3.1 解法 1:Reinforcement Learning
用 RL 硬 train

- :the agent's parameters
- actor 的輸出:network 寬度、深度等等
- Reward to be maximized:
舉例:
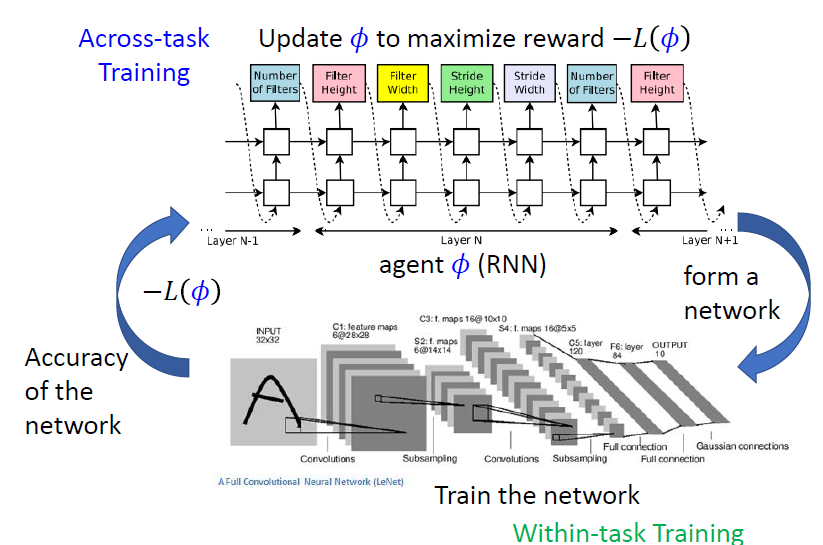
actor 是 RNN 架構;environment 為 network
- RNN 輸出網路架構(action)
- 搭建網路架構
- 測試網路的精確度(observation)
- 更新 RNN
4.3.2 解法 2:Evolution Algorithm

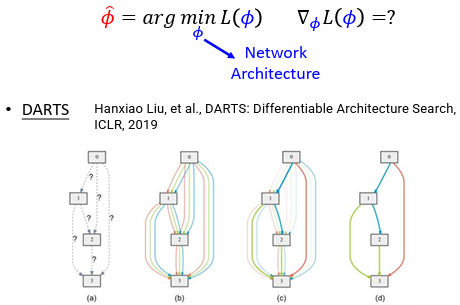
4.3.3 解法 3:DARTS
Differentiable Architecture Search(DARTS)方法修改 network architecture,使之可以微分
4.4 Data Augmentation
選擇 data(augmentation)作為 meta learning 要學習的參數
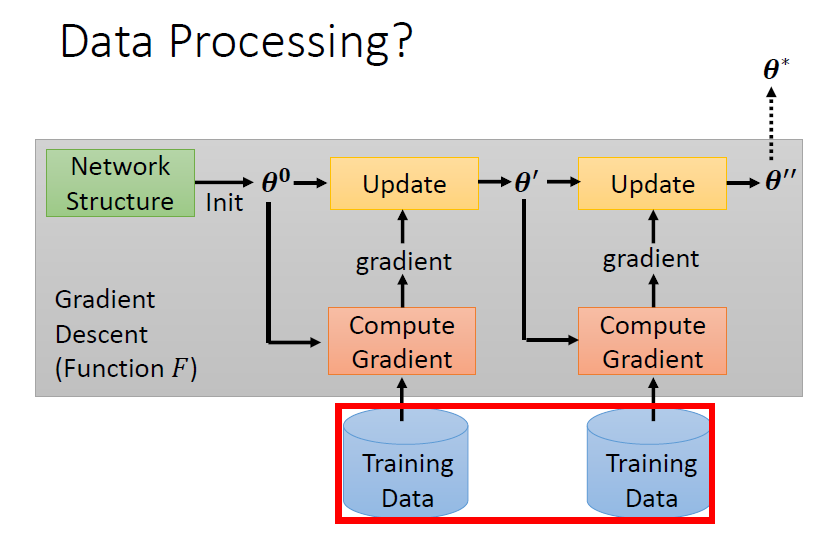
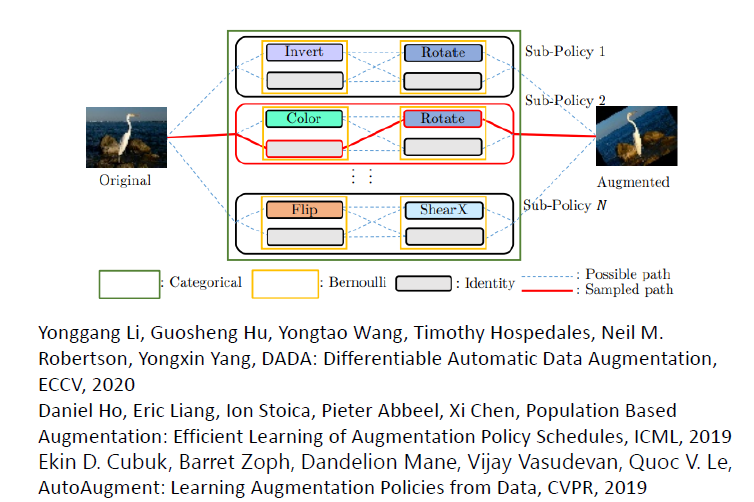
4.5 Sample Reweightnig
選擇 sample 的 weight 作為 meta learning 要學習的參數

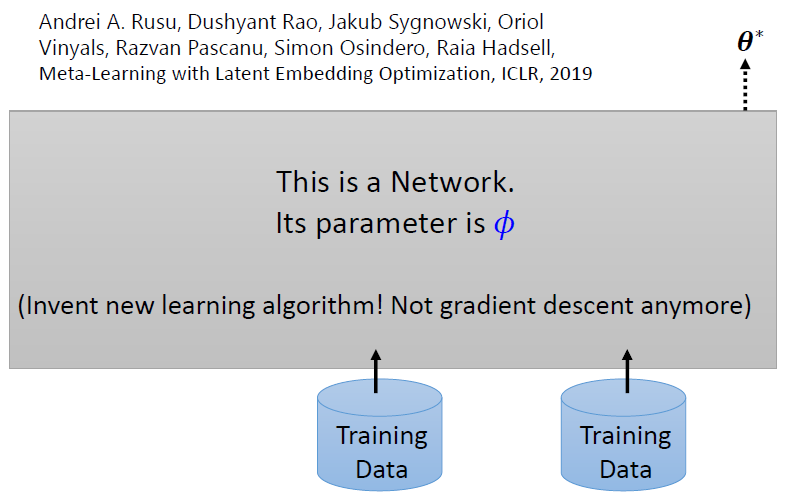
4.6 Beyond Gradient Descent
輸入數據,直接輸出模型
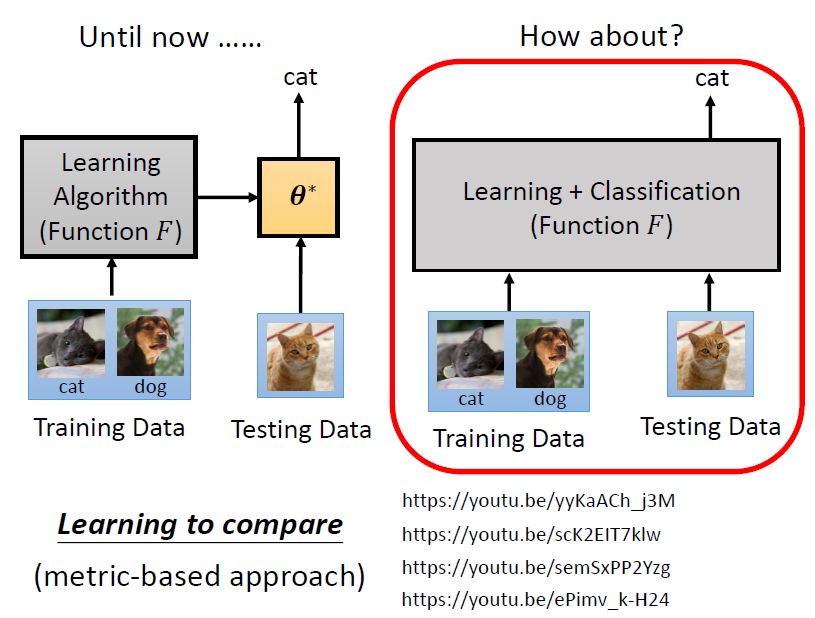
5. Learning to compare
learning to compare 直接輸入訓練資料和測試資料,學出 learning + classification,就直接輸出測試的結果
學習更多:
6. Application
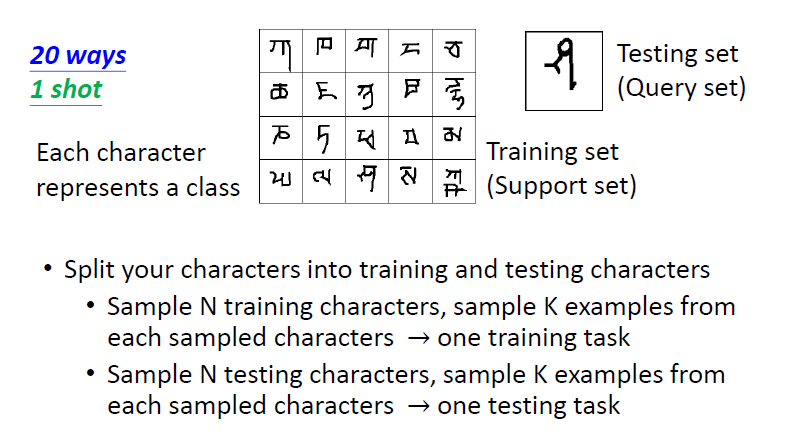
6.1 Few-shot Image Classification

- N-ways K-shot:N 個類別、每個類別 K 個樣本
- 在 meta learning 中,需準備多個 N-ways K-shot 的任務作為訓練任務與測試任務
一般做 meta learning 的實驗通常會使用 Omniglot 資料集

6.2 More application
更多 meta learning 應用可參考:http://speech.ee.ntu.edu.tw/~tlkagk/meta_learning_table.pdf